


Making Sense of Graphs with Watset
Making Sense of Graphs with Watset
This is my research contribution. There are many like it, but this one is mine. And it is a graph clustering algorithm that makes sense.

I always said that if you need external motivation to do Ph.D. studies, you will not make it anyway. But if one has motivation, time, and energy, what should they do and how to approach the unknown? In this post, I will share an anecdote from my experience.
Before the mid-2010s, natural language processing (or computational linguistics) was a kaleidoscope of brave ideas to make machines understand natural language with varying success. Researchers were doing their early experiments with machine learning, but most tasks were addressed using ad-hoc methods and different heuristics.

An Observation
In the 2010s, a lot of discussions were focused on getting big and high-quality lexical resources, such as dictionaries, thesauri, and ontologies. These resources described words, their meanings, and the relationships between them; most were built by teams of expert lexicographers. As a speaker of Russian, an under-resourced language at the time, I envied the vast area of lexical databases for English. At the same time, I observed a big success of crowdsourcing and Web-crawled datasets: Wikipedia, Wiktionary, Common Crawl, and many more.
I wanted to help and I felt that it would be great to capture structure in data to bootstrap dictionaries and thesauri. I started exploring different linguistic graphs using Graphviz and Gephi. And I noticed the following pattern that kept regardless of the language.
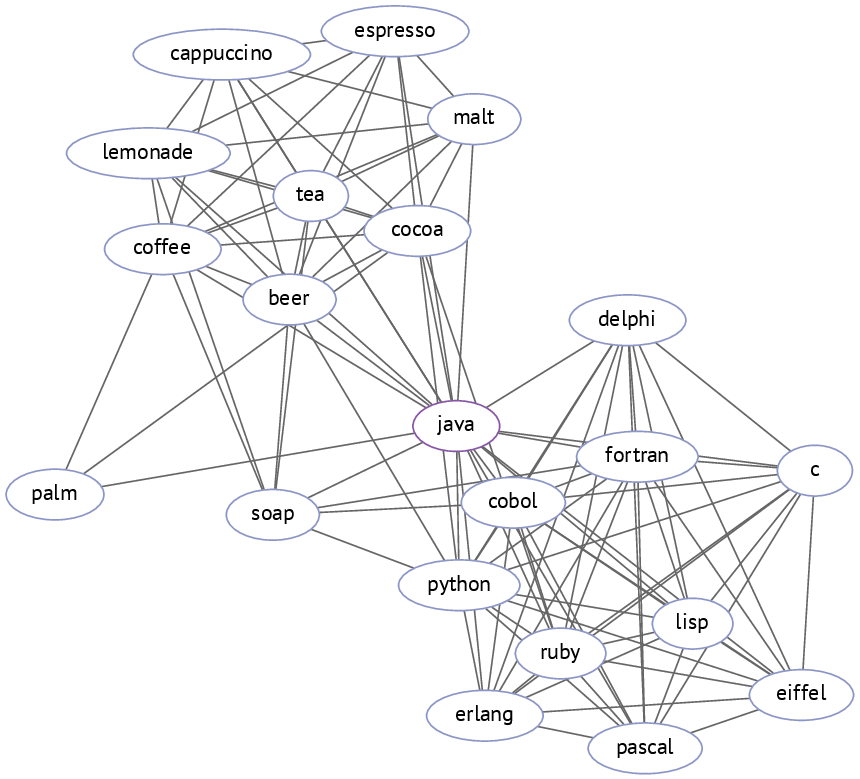
If you take a graph of semantically related words, pick a node, and then extract its neighborhood, you get a very clear illustration of how words can have multiple meanings. If we only could extract these structures, e.g., java as a drink and java as a programming language, we would be able to make a nice dictionary—without any human supervision!
Discovery is an amazing part of the research process but it is always disappointing to notice if somebody else managed to already publish a paper about the same phenomenon. I found that people had been inducing the word senses using exactly the same approach for quite a long time (Dorow & Widdows (2003), Biemann (2006)). You take a graph, pick a node, extract its neighborhood, run a clustering algorithm, and attribute each cluster to a separate meaning of the picked node.
I noticed that the prior work did not go further into reconstructing the discovered meanings into the WordNet-like graph, which was desirable at the time. I proposed the following approach. First, I built a new sense graph, the nodes of which were the discovered senses and the edges between pairs of nodes were drawn if the corresponding node senses were referring to each other in the clusters. Then, I performed clustering of this new graph, which resulted in sets of node senses, each of which represented a single meaning expressed by multiple words.
Watset
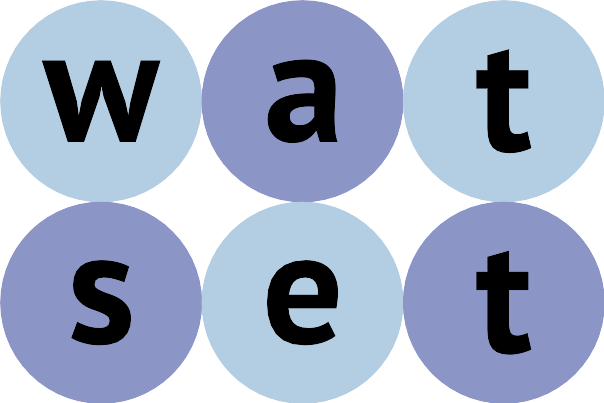
I called this algorithm Watset since it performs disambiguation (wat) of synonym sets (set). The algorithm takes a simple weighted graph and processes it in four steps:
it extracts and clusters a neighborhood of each node
it recovers which edge appeared in which cluster
it constructs the sense graph connecting these node senses
it clusters the sense graph to obtain clusters of senses
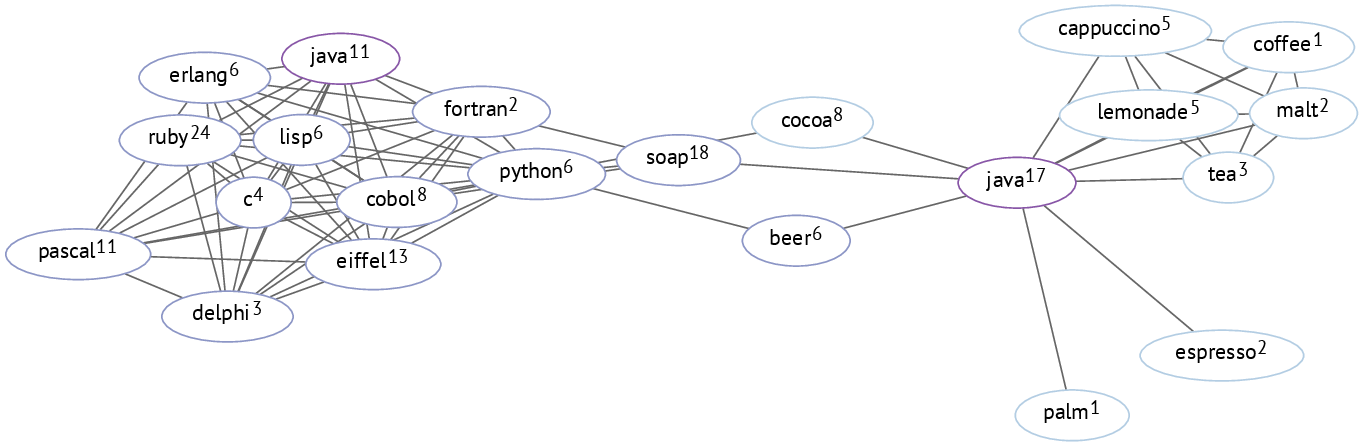
Our experiments showed that Watset outperformed all other methods in a variety of tasks, spanning from synonymy discovery to frame semantics. In the example above, Watset correctly identified two clusters: {c, cobol, cocoa, delphi, eiffel, erlang, fortran, java, lisp, pascal, python, ruby} and {beer, cappuccino, cocoa, coffee, espresso, java, lemonade, malt, palm, soap, tea}. Note that the polysemous word java appeared in two clusters, as expected, and the graph does not have to be weighted.
We published an initial paper at ACL in July 2017 and an improved and extended article in the MIT Press’ Computational Linguistics journal in 2019. Interestingly, a similar idea, but applied to social networks, was published as a paper at KDD in August 2017 by other authors (however I noticed that paper much later). It means that Watset is ubiquitous; it was a fantastic, rewarding, and motivating journey.
My implementation of Watset in Java which includes multiple alternative algorithms is available on GitHub, Maven Central, and conda-forge. I also made a nice interactive demo, feel free to play with it. Also, Watset was a part of my Graphs, Computation, and Language class.