



LLMFAO: Pairwise Human Ranking of Large Language Models
Sixty large language models, a dozen prompts, and a glimpse of human feedback.

In September 2023, I noticed a tweet on difficulties with the evaluation of large language models (LLMs), which resonated with me a lot. A bit later, I spotted a nice LLMonitor Benchmarks dataset of a small set of prompts and the corresponding completions from seventy different proprietary and open-source models. Of course, evaluation is hard, but I decided to make my attempt without running a comprehensive suite of hundreds of benchmarks.
Methodology
We have seen a similar problem in the recommender system and information retrieval evaluation. For instance, Google’s quality rater guidelines had 176 pages in December 2022 (and 170 pages in 2021). However, when you see the outputs of two different systems for the specific query, you can determine the better one using a smaller instruction. I decided to give pairwise comparisons a try on the data kindly provided by the llmonitor.com team:
I picked all the non-coding and non-redundant prompts, keeping 13 out of 19 initial prompts remained:
k8s,qft,vendor-extract,munchhausen,basic-sentiment,cot-apple,taiwan,sally,holidays,bagel,planets-json,blue,product-description. Only 58 out of 70 initial models remained.For each prompt, I computed pairwise Levenshtein distances between system outputs. Then, I assumed that it would be easier to compare not-very-similar responses rather than similar responses, so for each prompt and easy system, I extracted the three most dissimilar pairs, which resulted in 2,139 pairs in total.
I asked carefully chosen crowd annotators to evaluate every pair to determine the winner. If both models performed similarly well or poorly, it’s a tie. Five different annotators evaluated every pair according to the instruction; there were 124 annotators in total. I also asked GPT-3.5 Turbo Instruct and GPT-4 to do the same using a shorter evaluation prompt, but I subjectively found human performance to be superior.
Finally, I aggregated these comparisons using the Bradley–Terry model that estimated the item scores, allowing recovering the ranked list of items. As I wrote before, I do not understand why people were using Elo ratings in which the rankings depend on the comparison time, which is not the case there.
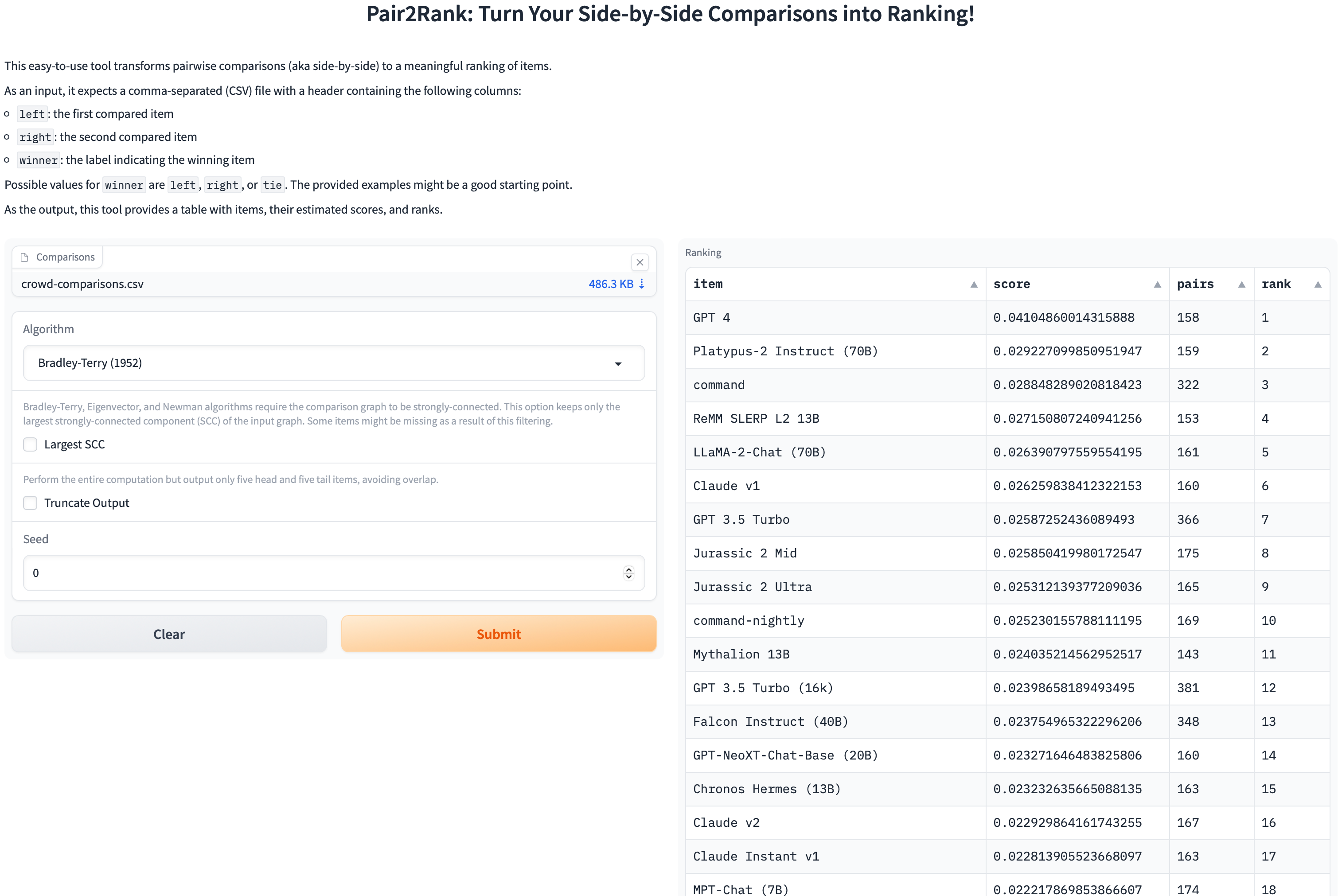
Also, I built Pair2Rank, a nicely looking tool that simplified the last step of my analysis, and hosted it on Hugging Face. It also has nice pairwise visualizations that did not fit in the screenshot, so I recommend giving it a try!
Results
I uploaded the complete results to the designated leaderboard. I got the following top-7 results according to the crowd annotators (open-source models were additionally boldfaced):
OpenAI’s GPT-4 (score: .041049)
Platypus-2 Instruct (70B) (score: .029227)
Cohere’s command (score: .028848)
ReMM SLERP L2 13B (score: .027151)
Meta’s LLaMA-2-Chat (70B) (score: .026391)
Anthropic’s Claude v1 (score: .026260)
OpenAI’s GPT 3.5 Turbo (score: .025873)
There was a large gap between the winner and the runner-up, and GPT-4 proved itself to be the best available LLM by the time of my analysis. The gap between the runner-ups was not that big. I was really surprised to see an open-source model in the top-3, so I additionally manually checked the output correctness. The runner-up model, Platypus-2 Instruct, performed really well, and my manual analysis confirmed it (but I cannot say the same about ReMM SLERP L2 13B). So, congratulations, Platypus team!
These seven models failed the following prompts:
GPT-4 did not pass only
bluePlatypus-2 Instruct (70B) did not pass
sallyandbluecommand did not pass
k8s,cot-apple,sally,holidays, andblueReMM SLERP L2 13B did not pass
k8s,cot-apple,sally,planets-json,blueLLaMA-2-Chat (70B) did not pass
basic-sentimentandblueClaude v1 did not pass only
sally(NB: Claude v2 did not passbasic-sentiment,sally, andblue)GPT-3.5 Turbo did not pass
sally,blue, andplanets-json
GPT-4, which had been the strongest LLM so far, correlated only moderately with the human judgements (Spearman’s ρ = .730); all other correlations were lower. I observed that the higher-ranked models performed significantly better than the lower-ranked ones. Since my pair sampling method gives more exposure to the models that tend to produce results dissimilar to others, and one poorly performing model could be compared only with other poorly performing models. In future work one has to sample additional pairs connecting different parts of the comparison graph.
Conclusion
Although I reported only the human judgements, I published the complete leaderboard and uploaded all the data and most of my code. Check out the GitHub repository called Large Language Model Feedback Analysis and Optimization (LLMFAO) and a Hugging Face Space called Pair2Rank. The repositories also contain the GPT-4 and GPT-3 evaluation responses as well as my sampled pairs and other intermediate artifacts.

Time flies fast and we hear about the new advancements in this area almost every day. So, unfortunately, my dataset does not feature the most recent models like Mistral AI and others (but I’d be very happy to add it to the comparison if I had their completions). Also, timing is currently a crucial factor in machine learning evaluation as all the open-source datasets might accidentally become training data if refreshed not frequently enough.